
AlphaGenome 釋出對生醫界的影響及其血液學應用:AlphaGenome 是什麼?重要嗎?
就在我還沒結束對 AlphaFold 強大的震撼,Google DeepMind 又釋出了 AlphaGenome 來用基因序列預測它的表現調節與變異下可能的疾病狀態,更讓我驚喜的是它們挑了個超難的 T 細胞急性白血病來試刀。


Google DeepMind 的 AlphaGenome 在 2026 年 1 月 28 日正式於《自然 Nature》期刊刊出。其實早在去年七月前,團隊就已經釋出這篇研究的 preprint,也有 Google 開發者讀書會錄了一個小時的討論影片。
這篇文章會是我自己慢慢讀之下的讀書筆記與心得,因為自己是位以臨床為主的血液科醫師,分子生物學稍有接觸但實務經驗不多,而生物資訊方面更有待精進,也希望有建議或想法的同好多多補充。
AlphaGenome 有什麼厲害之處?
基因是我們的遺傳資料,而基因怎麼樣表現,造就了各司其職的細胞。基因表現有異常,也會導致一系列的疾病。當我們拿到一段基因,就可以推知它怎麼樣表現,而基因有異常的狀況下,表現會如何改變,這就是「序列至功能模型 (sequence-to-function model, S2F)」試圖模擬的。
AlphaGenome 正是目前表現最佳 (state-of-the-arts, SOTA) 的 S2F。
在此之前,S2F 的挑戰有兩者:
廣度或深度的取捨:預測精準至各別鹼基但短 (≤ 10 kb) 的序列 (e.g.,
SpliceAI,BPNet,ProCapNet) v. 長序列 (200–500 kb) 但解析度低 (128-bp or 32-bp bins) 的預測 (e.g.,Enformer,Brozoi)泛用或特異的衡量:需要有夠多的基因組資料並連結表現型,才能知道正常與病態和非病態的變異 (variant effects)。知道什麼是正常,也要知道什麼是異常。
AlphaGenome 在基因表現的各階段,細緻的過程包括轉錄 (transcribe)、剪裁 (splicing),它的基因、組蛋白、染色質能否被打開還是收束等,與現存的預測工具相比,預測的結果最接近實際上的觀察值,達到了「更廣、更深、更強 (Latus, Profundus, Fortius)」(容我改一下奧運愛用拉丁文 Citius, Altius, Fortius),套句現在流行的話,就是可以克服取捨之間的困境,說出「小孩子才做選擇,大人我全都要」。
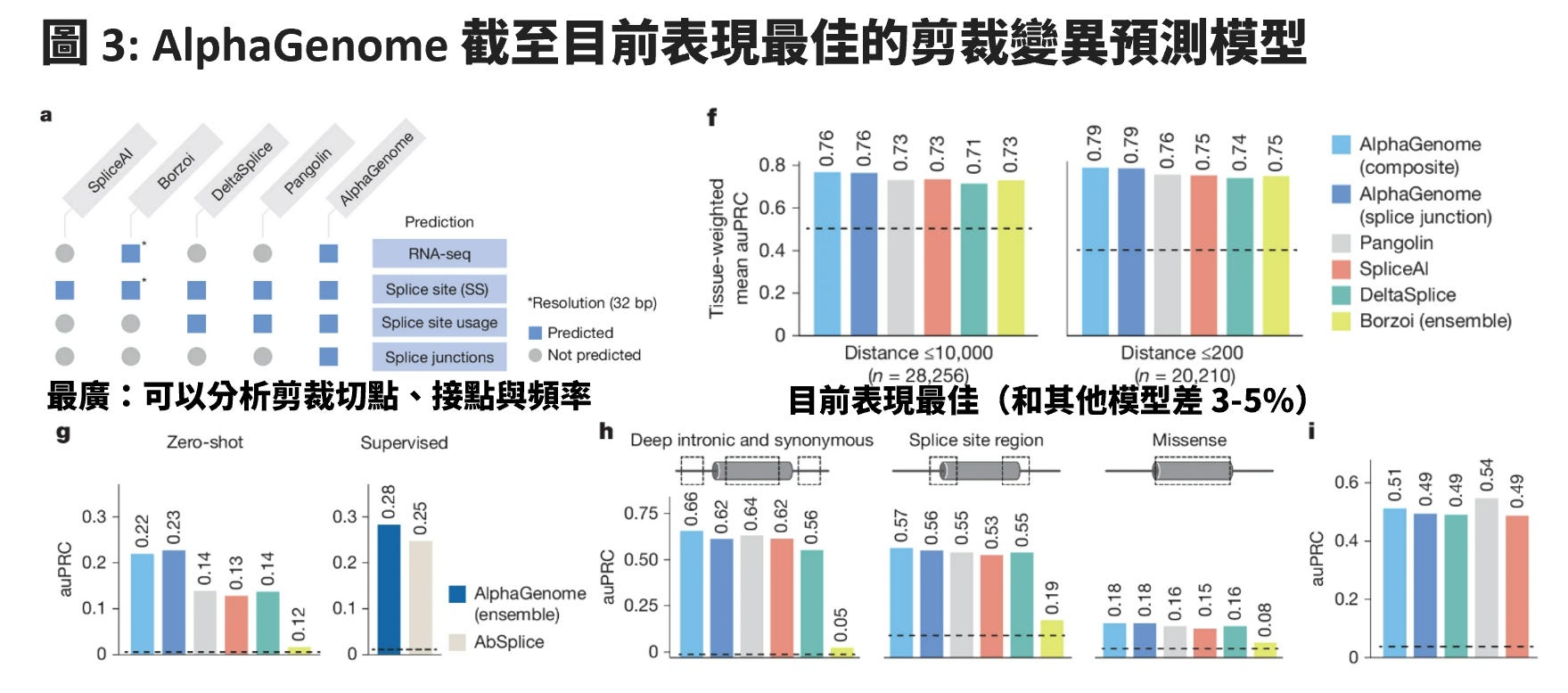
鉅亨網上聲稱「過去的基因預測模型往往只能專注於單一的生物過程,但 AlphaGenome 成功構建了一個統一的預測框架」,我覺得又講得太滿。同樣是 Google 旗下,但屬於不同子公司的 Calico Life Sciences LLC 開發出的 Borzoi 就可以處理轉錄資料 (e.g., CAGE, PRO-cap), 剪裁資料 (e.g., splice site, site usage, splice junction) 與 DNA 可及性資料 (e.g., DNase-seq, ATAC-seq),而其實也是 DeepMind 做的 Enformer,也可以從 DNA 可及性、染色質構型與轉錄因子結合位來進行 variant effect 預測。科學沒有什麼一蹴可幾,迭代而已。
再仔細看 AlphaGenome 和其他模型的表現差異,在剪接上與 Pangolin 差約 3 個百分點,其他模型 3-5%。以它的廣度與深度兼俱來說沒有問題,至於強度(預測能力)的話,是否可以達到八成以上的預測能力,還有待後續。有些誇大的媒體聲稱「能讀懂讓科學家一頭霧水的 98% DNA」,實在太過。目前要這些佔了 98% DNA 的 non-coding region 還是需要實驗證實,預測模型可以讓我們在實驗中更有機會釐清機轉,而無法完全取代過程。過當的簡化讓人對於當前技術有虛妄的認知,雖然不可取,樂觀一點想,這也不失為一種能鑑別個體識讀能力與科學技術掌握度的線索。
AlphaGenome 的邏輯流程
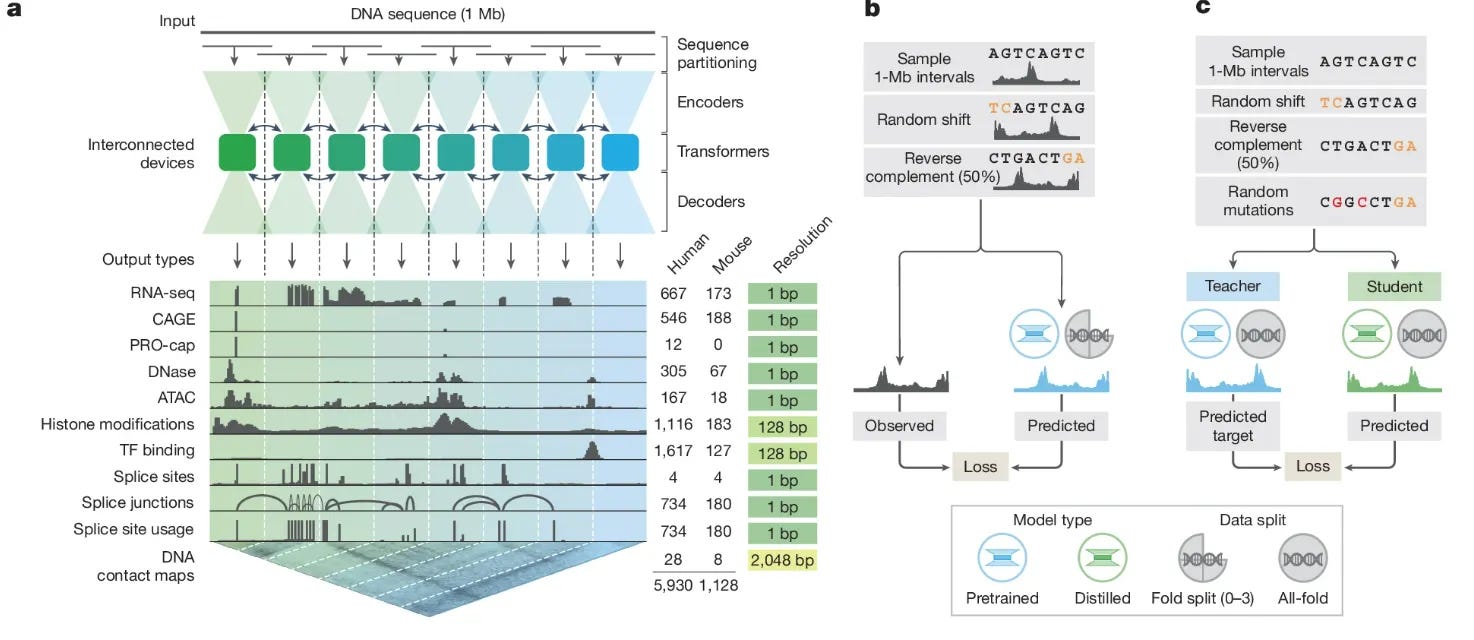
AlphaGenome 的輸入、處理與輸出流程參見左圖 (a)
輸入 (input) : 輸入最多 1 Mb 的 DNA 序列,並進行序列切分 (sequence partitioning) 以進行平行運算 (sequence parallelism),產出許多條大約 131 kb 的基因片段(genome tracks)。
加密-轉換-解密 (細節參見文中附圖1)
加密 (encoder):利用卷積神經網絡(Convolutional Neural Network, CNN)的卷積層 (convolutional blocks) 提取局部訊息,再用 U-Net-style design 來兩倍兩倍壓縮資訊量直至 2 的 7 次方,解析度到 128 bp,再丟到轉換塔 (Transformer tower)。
轉換塔 (Transformer tower):以 128 bp 解析度來進行成對比較,並進行層常規化 (layer normalization)、按行注意力計算 (Row-wise attention) ,再送到多層感知器 (Multi-Layer Perceptron, MLP),而這也正是 AlphaFold 所使用的運算法。
解密 (decoder):再次使用 CNN 並解壓縮至 1 bp 解析度。
輸出 (output):依生物學上基因表現的過程輸出 (task-specific output)。
在機器學習的訓練過程中,輸入經過交插驗證的基因折 (fold),方便進行機器學習。在訓練前期 (pretraining process),先丟入部份基因折 (fold split) ,並產生出特定基因折 (fold-specific) 與具有所有基因折 (all-fold) 的教師模型 (teacher model)。
在蒸餾階段 (distillation process),再由教師模型用全折 (all-hold) 訓練學生模型 (student model) ,而輸入的序列更包括變異的序列,讓模型可以了解正常基因表現與變異之下會有的影響。
之後會再 AlphaGenome 在不同基因表現步驟的預測性,以及血液學 T-ALL 基因表現變異的實測。